Pandas 工具介紹
本文由顏密編輯
本文摘自〈Pandas〉,由顏密統整後撰文。
簡易介紹:
pandas,是為了於Python程式語言中進行資料分析而設計的函式庫,主要可用於單維度(Series)和二維度(DataFrame)的資料處理。pandas可應用於多種不同目的資料分析,如文學作品統計分析、銷售趨勢分析、交通事故統計分析等。其中,DataFrame是最為常見的資料型態,主要用來處理二維度資料,也就是同時具有欄(columme)與列(row)的表格式資料集,應用於讀取網頁表格、資料庫和制表符分隔值格式檔案(如常見的csv和tsv檔)。故本文專注於說明幾個如何以pandas分析DataFrame的主要功能,如敘述性統計、數值或浮點數組成欄位的計算。
安裝:
這邊利用Anaconda為安裝例子,很多人說Anaconda像是Python懶人包,因本身就自帶Python軟件以及pandas、NumPy等,算是最簡單的安裝方式,也是官方推薦的其中一種。因此只需下載並安裝Anaconda即可 。
基本操作:
在安裝完成後,開啟Python編譯器,如Jupyter Notebook,之後輸入import pandas as pd(如圖一所示,pd為pandas的縮寫)。匯入模組後,本文以anochima於GitHub所提供之銷售資料分析為例 進行說明。
圖一 匯入pandas
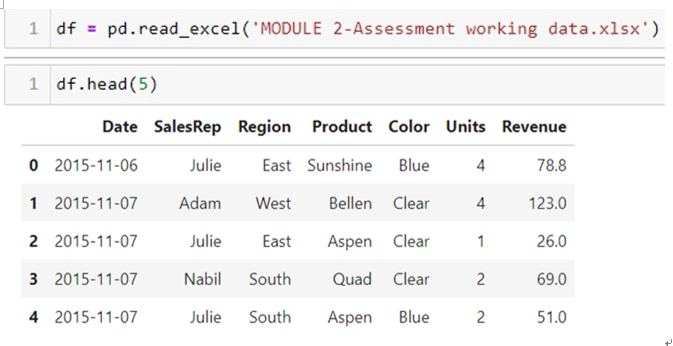
做任何資料分析之前,最重要步驟為「讀入資料」。在pandas裡,如圖二第一行所示,以pd.read_excel()的方式讀入xlsx檔案 ,讀取後可藉由輸入df.head(),顯示前幾項資料(df為DataFrame的簡寫),括弧中可以輸入數值,像df.head(5)為資料前五項。
圖二 讀取資料
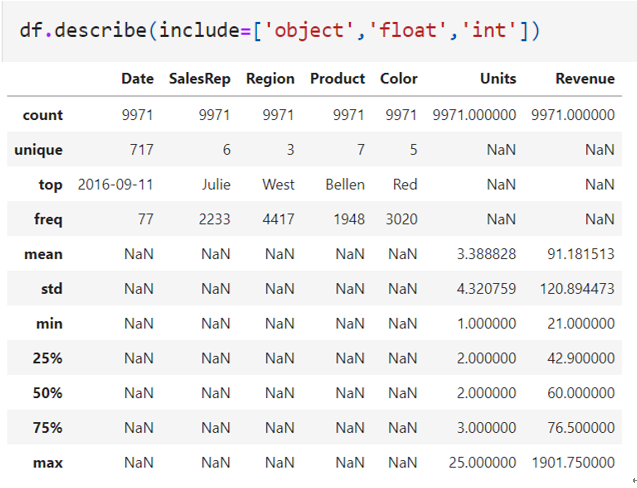
讀入資料後,首先本文介紹如何以pandas進行敘述性統計,如圖三所示,輸入df.describe()以查看讀入資料的統計資訊,其中,使用者可於include參數中選取為特定資料型態組成的欄位,如數值或浮點數。統計結果可以觀察到2015年至2017年最少的收入(Revenue欄位)為21,最大為1901,而賣最好的顏色(Color欄位)為紅色(top=Red, freq=3020)。
圖三 查看敘述 性統計結果
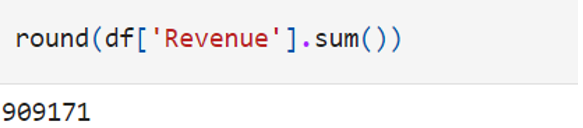
隨後,本文介紹如何用pandas以數值或浮點數組成欄位計算,例如計算2015至2017年的總收入,可藉由輸入round(df[' Revenue'].sum())(圖四)進行整個Revenue欄位的計算。sum的功能為加總某欄中的所有值,而round則可將加總後的值做四捨五入。
圖四 Revenue欄位加總及四捨五入
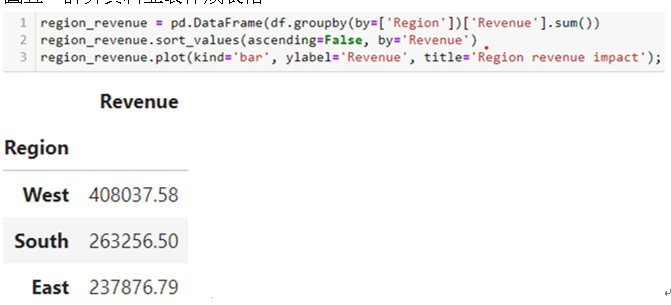
最後,本文藉由「分析及可視化各地區收入」實例,介紹pandas較進階的用法。透過groupby的方式將資料依據自己要的欄位分組,可幫助在數據解讀上更加一目瞭然。sort_values()函數可以以升冪或降冪給指定對象進行排序,這裡的ascending=False代表適用降冪方式排列(如圖五第二行)。
圖五 計算資料並製作成表格
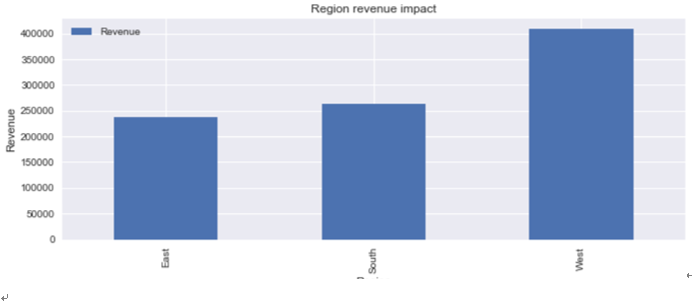
為了更直觀的觀察各地區收入之差異,可藉由pandas提供的plot()功能將各區收入視覺化。kind設置為直條圖(bar),ylabel可以y軸上輸入標籤,標籤為Revenue,title就是標題(如圖六)。
圖六 各地區收入之視覺化結果
結語:
本篇介紹了一些基本功能操作,以及以實際分析做為範例,其實pandas的功能既強大也很齊全,如果能將整套學起來,相信能在資料分析上有更大的幫助。